ASCII
http://www.robelle.com/library/smugbook/ascii.html
- character encoding
- short for: American Standard Code for Information Interchange
-
ASCII 码一共规定了128个字符的编码
- Wordstar

- MS-DOS
question
“plain text == ascii == characters are 8 bits”?
only for english

- In ASCII, every letter, digits, and symbols that mattered were represented as a number between 32 and 127.
- 1 byte
- 只占用了一个字节的后面7位,最前面的一位统一规定为0 - 7位来编码,8位来传输
- 有些软件会使用第一位。
- wordstar-indicate the last letter in a word
- [0, 31] called unprintable
- 大部分已经废弃
- but remain some :such as the carriage return, line feed and tab codes.
- used for control characters, 如
- 7 which made your computer beep
- 12 which caused the current page of paper to go flying out of the printer and a new one to be fed in
- 大部分已经废弃
- [32, 127] are printable–Ninety-five of the encoded characters
- 表示可打印的字符(a-z, A-Z, 0–9, +, -, /, “, ! etc.)
- 32-space
- 65-“A”
- 不支持其他字符
- 没有带变音符的拉丁字母(如 é 和 ä ),也不支持像希腊字母(如 α、β、γ)、西里尔字母(如 Пушкин)这样的其他欧洲文字
- 更加不要说中文了
1
2
//make a bel
echo ^G
del 为什么删除键作为控制字符, 编码为 127
- 打孔机的纸带中,对应位为 0 就不打孔,对应位为 1 就打孔。
- 一卷全新空纸带上完全没有孔,自然表示全 0,也就对应于 ASCII 的控制字符 Null。
- 那在打孔机上打错字符时怎么办
- 纸带中不能将已打的孔填上,于是当打错字干脆将其全部打孔,表示这一个字符被省略或者删除。
- 全部打孔就是二进制的 7 个 1,对应十进制编码 127

Line Feed && Carriage Reture

- Line Feed
- Classic Mac OS, OS-9, FLEX (and variants).
- CR+LF
- DOS and Windows, and by Application Layer protocols such as FTP, SMTP, and HTTP
- history
- 打字机要求”Carriage Return” + “Line Feed”
- “Carriage Return”–把打印机头移到最前面
- “Line Feed”移到新一行
- 打字机要求”Carriage Return” + “Line Feed”
EOF
end of file的缩写,表示”文字流”(stream)的结尾。这里的”文字流”,可以是文件(file),也可以是标准输入(stdin)
- EOF不是特殊字符,而是一个定义在头文件stdio.h的常量,一般等于-1
1
2
3
4
5
6
#define EOF (-1)
int c;
while ((c = fgetc(fp)) != EOF) {
//do something
}
from ascii to unicode
- 不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样
- 亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右
- 世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号
- Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。
- 每个符号的编码都不一样
- 只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
question
- Unicode 是16位编码?
- 每个字符占用16位?可以表示65,536个字符?
- 如何才能区别 Unicode 和 ASCII ?
- 计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
unicode
windows 通过charmap查询
- character encodings
- providing a unique code point—a number, not a glyph—for each character
- leaves the visual rendering (size, shape, font, or style) to other software
utf-16
起源于UCS-2 (for 2-byte Universal Character Set)
- languages:
- java
- JavaScript/ECMAScript
- system:
- windows use it often
- 近两年向UTF-8靠近
- Unix-like systems not like it
- windows use it often
- encoding using 65,536 (216) values
- 2 bytes (16 bits) per character
- 不兼容ASCII
- on web:
- 0.005% (less than 1 hundredth of 1 percent) of web pages
- UTF-8, by comparison, is used by 97% of all web pages
high-endian UCS-2 or low-endian UCS-2
UTF-8 演进史

1
[ITA 2, FIELDATA] ---> ASCII ----> GB2313 ----> Unicode[US-2, UTF-16] -----> Unicode[UTF-8]
UTF-8
- memory:1-4字节
- 最流行的编码方式
- 97% of all web pages
- 兼容ASCII
- 对于单字节的符号和ASCII一样

解读
- 字节
- 如果一个字节的第一位是0,则这个字节单独就是一个字符;
- 如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节
- 对于单字节的符号,字节的第一位设为0
- 对于n字节的符号(n > 1),
- 第一个字节的前n位都设为1,
- 第n + 1位设为0,
- 后面字节的前两位一律设为10。
- 剩下的没有提及的二进制位,全部为这个符号的 Unicode 码
sample
- windows打开charmap,搜索一个汉字

endianness of an encoding
1
2
3
4
//对于一个32位整数1,不同的CPU架构会有不同的存储方式:
00000000 00000000 00000000 00000001
//或者
00000001 00000000 00000000 00000000

大端
- 高位在前
- 最低位放在最后一个位置
- TCP/IP 协议栈是按照 Big Endian 来设计的,而 X86 机器多按照 Little Endian 来设计的,因而发出去的时候需要做一个转换
小端
- 低位在前
- 最低位放在第一个位置
1
2
3
4
5
6
//UTF-8编码是变长的,用8~32位(1~4字节)表示,有固定的位置来表示是几个字节:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
//字节头部识别就是前面的0,110,1110,11110表示字节数
BOM
- BOM也是Unicode标准的一部分,有它特定的适用范围。
- 通常BOM是用来标示Unicode纯文本字节流的,用来提供一种方便的方法让文本处理程序识别读入的.txt文件是哪个Unicode编码(UTF-8,UTF-16BE,UTF-16LE)
- Windows相对对BOM处理比较好,是因为Windows把Unicode识别代码集成进了API里,主要是CreateFile()。打开文本文件时它会自动识别并剔除BOM。
bom(byte order mark)
Unicode 不使用 U+FFFE,在文件开头加一个 BOM 即可区分各种不同编码
UTF-8 with bom https://stackoverflow.com/questions/2223882/whats-the-difference-between-utf-8-and-utf-8-without-bom

- UTF-32 编码
- 0x00 00 FE FF, 大端
- 0xFF FE 00 00, 小端
- UTF-16
- 0xFE FF, 大端
- 0xFF FE, 小端
- UTF-8
- 0xEF BB BF –《其实我无所谓》

- 辅助作用?
- UTF-8 对BOM无要求
- UTF-8没有大小端的困扰
- bom可以标识输入流/文本以UTF-8编写,方便推测
- UTF-8 对BOM无要求
- 0xEF BB BF –《其实我无所谓》
JNI
在jni调用中我们经常用到GetStringUTFChars
1
2
3
4
5
6
7
8
JNIEXPORT jobjectArray JNICALL
Java_com_xxx_symbolkit_symbol_jni_ELFJni_getSymsBySoFile(JNIEnv *env, jclass clazz, jstring so_path) {
const char *path = env->GetStringUTFChars(so_path, 0);//转码UTF-8
//do something~~~~~~
env->ReleaseStringUTFChars(so_path, path);
return array;
}
字符串操作函数
- GetStringUTFChars
- const char * GetStringUTFChars(JNIEnv *env, jstring string,jboolean *isCopy);
- Returns a pointer to an array of bytes representing the string in modified UTF-8 encoding
- GetStringChars
- const char * GetStringChars(JNIEnv *env, jstring string,jboolean *isCopy);
- Returns a pointer to the array of Unicode characters of the string
- actually UTF-16
isCopy参数
- JNI_FALSE
- 指向的是JVM中的同一份数据
- 不一定会拷贝
- 本地代码决不能修改字符串的内容, - 否则JVM中的原始字符串也会被修改, - 这会打破JAVA语言中字符串不可变的规则
- JNI_TRUE
- 一定会拷贝
- 一定要调用release
- void ReleaseStringUTFChars(JNIEnv *env, jstring string,const char *utf);
- void ReleaseStringChars(JNIEnv *env, jstring string, const jchar *chars);
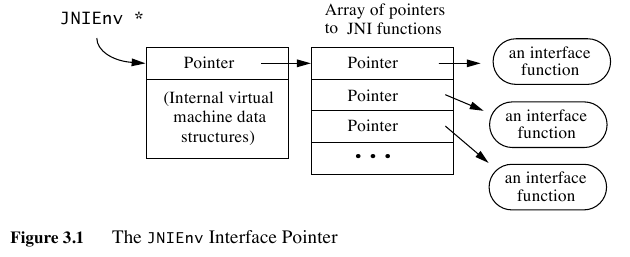
不要对JNIEnv做任何假设
Java layer objects as opaque references(pointer) passed to the JNI layer
JNIEnv is just interface
there are some many vms
- 虚拟机始祖:SunClassic/ExactVM
- 武林盟主:HotSpotVM
- 小家碧玉:Mobile/EmbeddedVM
- 天下第二:BEAJRockit/IBMJ9VM
- 软硬合璧:BEALiquidVM/AzulVM
- 挑战者:ApacheHarmony/GoogleAndroidDalvikVM
- 没有成功,但并非失败:MicrosoftJVM及其他
- 百家争鸣
- JamVM:http://jamvm.sourceforge.net/·
- CacaoVM:http://www.cacaovm.org/·
- SableVM:http://www.sablevm.org/·
- Kaffe:http://www.kaffe.org/·
- JelatineJVM:http://jelatine.sourceforge.net/·
- NanoVM:http://www.harbaum.org/till/nanovm/index.shtml·
- MRP:https://github.com/codehaus/mrp·
- MoxieJVM:http://moxie.sourceforge.net/
周志明. 深入理解Java虚拟机:JVM高级特性与最佳实践(第3版) (华章原创精品) (Chinese Edition)
java string && c++ string object
stirng literal
- actually calling intern() method on String
- references internal pool of string objects
- 运行时常量池,在runtime期间亦可以动态添加
- if same value exist, no new object could be created
- references internal pool of string objects
1
String str = “GeeksForGeeks”;

String object
- JVM is forced to create a new string reference, even if “GeeksForGeeks” is in the reference pool.
1
String str = new String(“GeeksForGeeks”);
c, c++
- C++98 中有 char 和 wchar_t 两种不同的字符类型,
- 其中 char 的长度是单字节,
- 而 wchar_t 的长度不确定。
- 在 Windows 上它是双字节,只能代表 UTF-16,
- 而在 Unix 上一般是四字节,可以代表 UTF-32
- C++11 引入了 char16_t 和 char32_t 两个独立的字符类型(不是类型别名),分别代表 UTF-16 和 UTF-32
- C++20 将引入 char8_t 类型,进一步区分了可能使用传统编码的窄字符类型和 UTF-8 字符类型
java String char to byte
为了节约String占用的内存
- jdk9新特性
- 在大多数Java程序的堆里,String占用的空间最大,并且绝大多数String只有Latin-1字符,这些Latin-1字符只需要1个字节就够了
- before
- JDK9之前,JVM因为String使用char数组存储,每个char占2个字节,所以即使字符串只需要1字节/字符,它也要按照2字节/字符进行分配,浪费了一半的内存空间
- after
- JDK9:一个字符串出来的时候判断,它是不是只有Latin-1字符,如果是,就按照1字节/字符的规格进行分配内存,如果不是,就按照2字节/字符的规格进行分配(UTF-16编码),提高了内存使用率
GBK, 半角&&全角
GBK
- 最早的中文字符集标准是 1980 年的国标 GB2312,
- 其中收录了 6763 个常用汉字和 682 个其他符号
- 与 ASCII 兼容
- 由于 GB2312 中本身也含有 ASCII 中包含的字符,在使用中逐渐就形成了“半角”和“全角”的区别
- 国标字符集后面又有扩展,这个扩展后的字符集就是 GBK
- 中文版 Windows 使用的标准编码方式
原因
- 历史原因
- 排版
1
2
3
4
5
//全角
val testing = true
//半角
val testing = true
「全角」与「半角」两个术语应该都是从日本来的
- JIS X 4051《日本語文書の組版方法》里面,将全角定义为「汉字一文字的外框」,半角定义为「字宽为全角二分之一的文字之外框」
at last: three button is enough



人类社会不断发展,技术日新月异,三个按键足够了

references
“line feed” and a “carriage return”?